
Stability AI 最近推出了Stable Diffusion XL 1.0,这是一款突破性的文本到图像生成模型。该模型能够生成任何风格的高质量、逼真的图像,并能处理对图像模型来说通常具有挑战性的复杂概念。通过简单的提示,SDXL 1.0在各种平台上提供高质量的输出,开启了数字艺术和内容创作的新时代。
您可以在 Clipdrop 上免费在线访问 Stable Diffusion XL,或者从其 Hugging Face 仓库 下载模型进行本地使用。
在这篇文章中,我将指导您如何使用 Stable Diffusion web UI 运行 SDXL 1.0。
获取 Stable Diffusion XL 模型
以下是模型的直接链接(可能会更改):
- Stable Diffusion XL Base
- sd_xl_base_1.0.safetensors
- sd_xl_base_1.0_0.9vae.safetensors
- sd_xl_offset_example-lora_1.0.safetensors:此 LoRA 模型修复了训练扩散模型时的一个错误。
- Stable Diffusion XL Refiner
理解模型和流程
在开始之前,重要的是要理解 SDXL 1.0 的工作流程。以下是官方的描述:
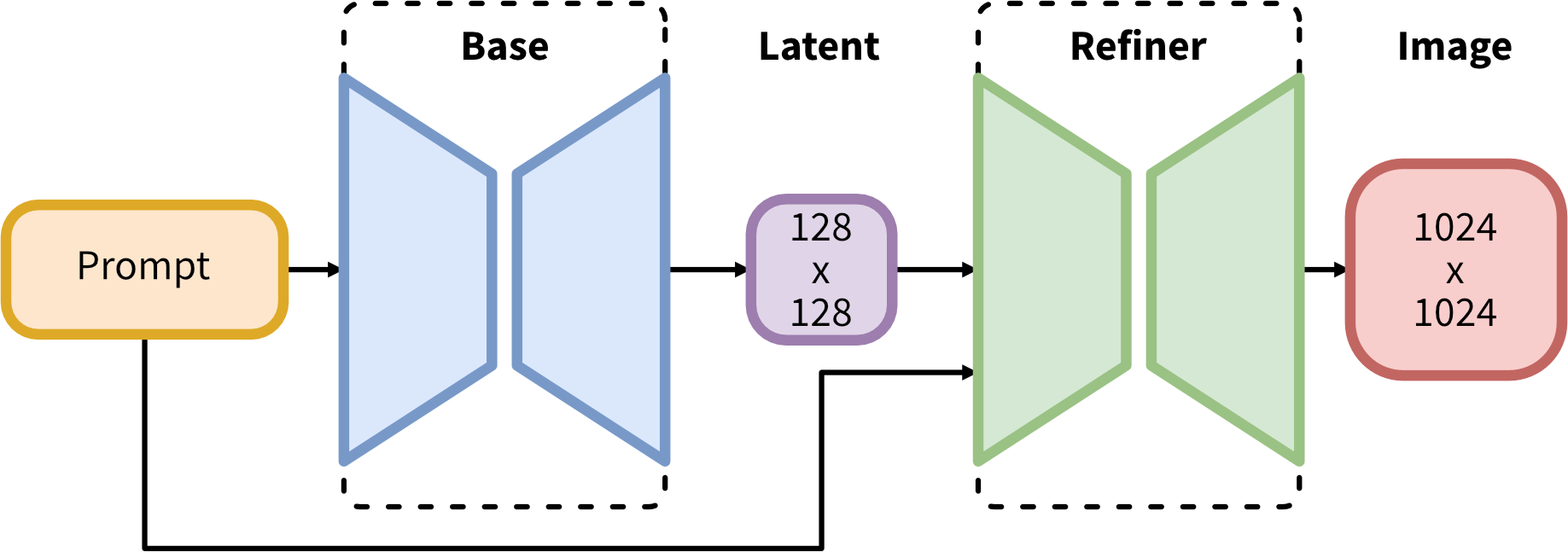
SDXL 采用了一个用于潜在扩散的专家集合流程。首先,Base 模型生成(噪声)潜在变量,然后使用专门的模型进行最后的去噪步骤。Base 模型也可以作为一个独立的模块使用。
另外,可以使用两阶段流程。首先,基础模型生成所需输出大小的潜在变量。然后,专门的高分辨率模型应用一种叫做 SDEdit 的技术到第一步生成的潜在变量上,使用相同的提示。这种技术比第一种稍慢,因为它需要更多的函数评估。
源代码可以在 Stability AI 的 GitHub 上找到。
使用 Stable Diffusion WebUI 运行 SDXL 1.0
Stable Diffusion web UI 是一个基于 Gradio 库的强大的浏览器界面,用于 Stable Diffusion。最新版本 1.5+ 支持 Stable Diffusion XL 1.0。
如果您是 Stable Diffusion web UI 的新用户,可以按照官方指南安装并运行它。如果您已经安装了它,只需使用 git pull 将其更新到最新版本。
接下来,将下载的 Base 模型和 Refiner 模型放入 Stable Diffusion web UI 的 models/Stable-diffusion 文件夹中,并将下载的偏移模型放入 models/Lora 文件夹中。
现在您已经准备好了。
在 Stable Diffusion Web UI 中使用 Stable Diffusion XL 1.0 生成图像
根据官方的描述,最好先用基础模型生成图像,然后用 Refiner 模型进行细化。
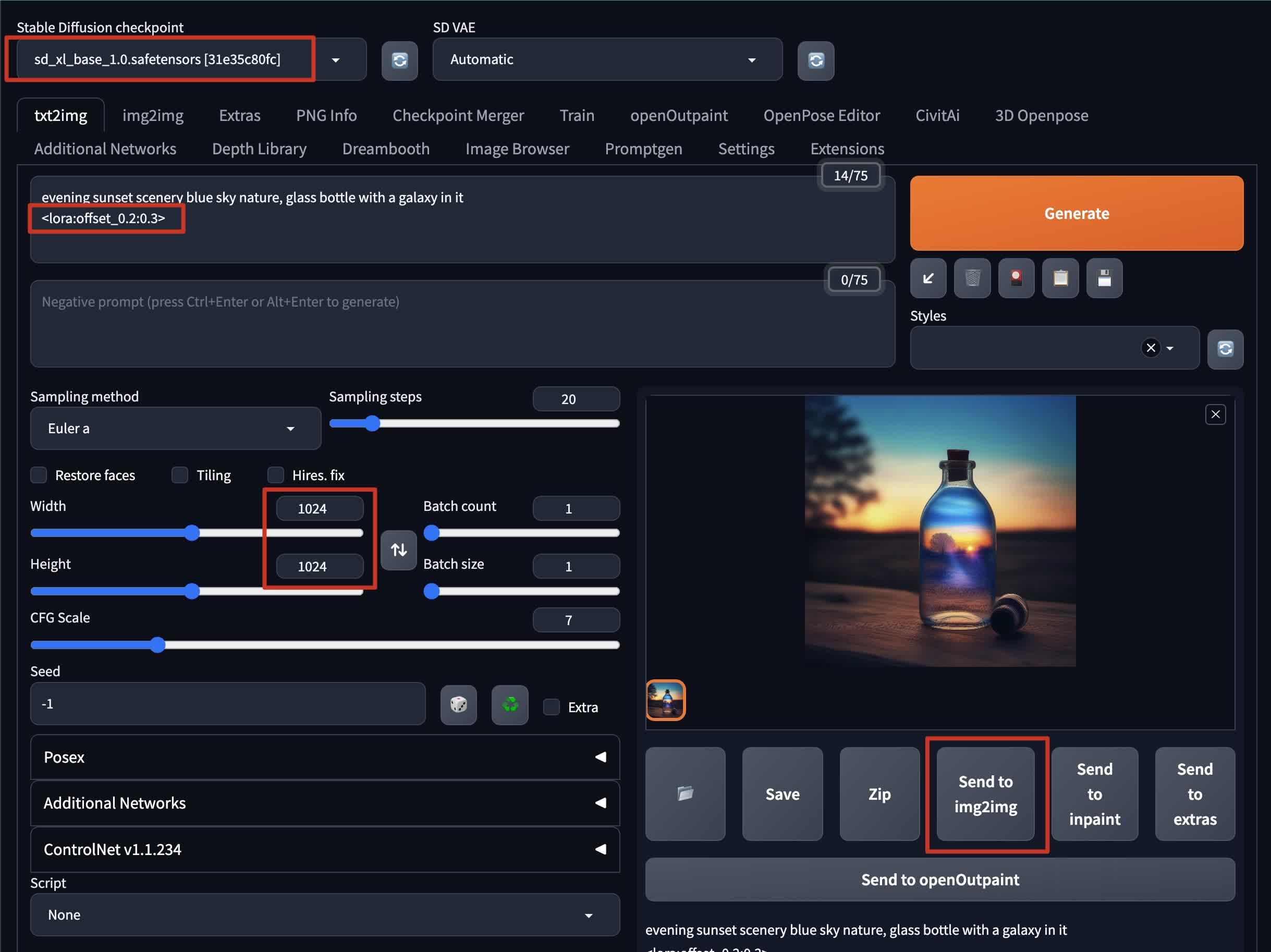
在 txt2img 模式下生成基础图像:
- 将检查点设置为
sd_xl_base_1.0.safetensors - 在提示框中写一个提示,并附加 Offset LoRA 模型:
<lora:offset_0.2:0.3> - 将大小设置为 1024x1024。这是推荐的大小,因为 SDXL 1.0 是在比前一版本更高质量的数据上进行训练的。
- 生成图像
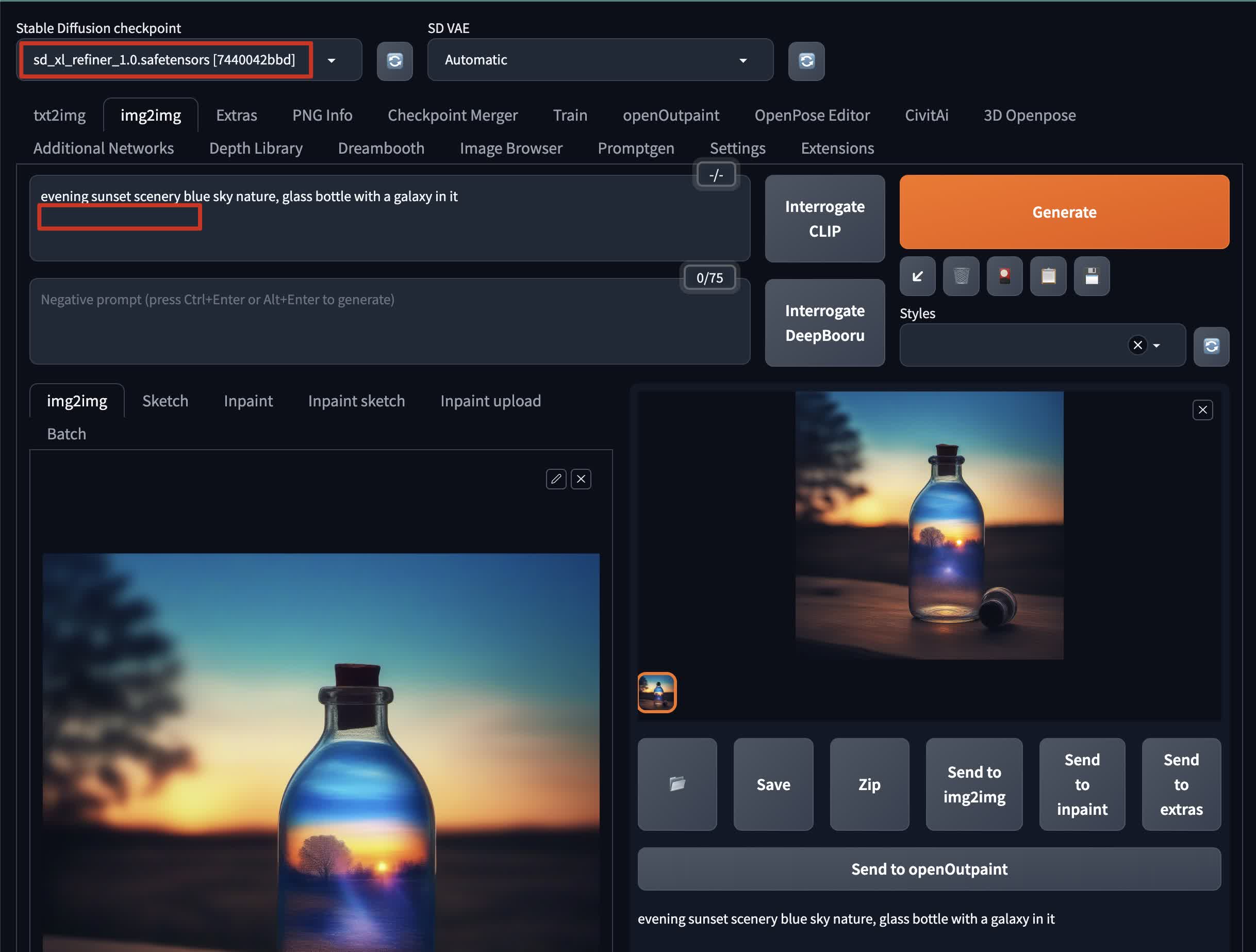
一旦你有了基础图像,你可以用 Refiner 模型来细化它:
- 将基础图像发送到 img2img 模式
- 将检查点设置为
sd_xl_refiner_1.0.safetensors - 从提示中移除 Offset Lora 模型
- 如果你希望结果尽可能与基础图像相同,将去噪权重设置为低于
0.2 - 可选的,你可以在 img2img 模式的
Script部分启用SD Upscale进一步细化和提高分辨率。
恭喜!你刚刚在 Stable Diffusion web UI 中使用 Stable Diffusion XL 1.0 生成了一张图像。
