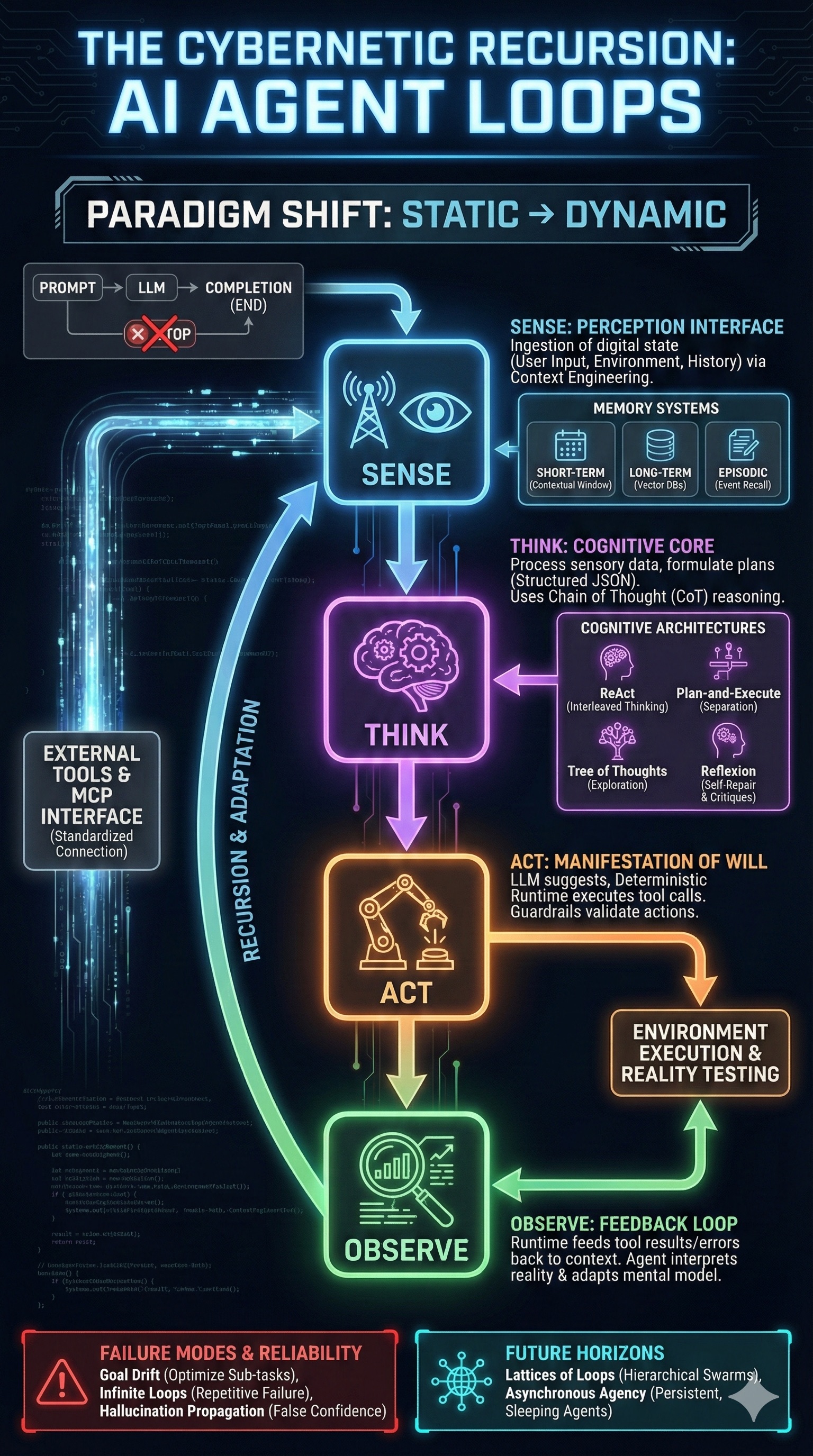
Artificial Intelligence is transitioning from static text generation to dynamic agency. In the traditional paradigm, Large Language Models (LLMs) operated as stateless engines—input a prompt, receive a completion, and the process ends. The emergence of the AI Agent Loop breaks this linearity by wrapping the reasoning engine in a recursive control structure. This allows models to perceive their environment, formulate plans, execute actions through tools, and refine their internal state based on feedback.
Basic Agent Loop Logic
To understand how an agent functions at a code level, here is the fundamental "Sense-Think-Act-Observe" loop implemented in Python.
def run_agent(task):
context = [{"role": "system", "content": "You are an autonomous agent."}]
context.append({"role": "user", "content": task})
while True:
# Think: Generate reasoning and next action
response = llm.generate(context)
context.append({"role": "assistant", "content": response})
if response.is_final_answer:
return response.answer
# Act: Execute tool call
for tool_call in response.tool_calls:
# Observe: Get feedback from the environment
result = execute_tool(tool_call)
context.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": str(result)
})
Theoretical Foundations: From OODA to Agentic Loops
The concept of the agent loop traces back to decision cycles observed in biological organisms and military strategy.
The OODA Loop and Cognitive Maneuverability
The primary ancestor of the AI agent loop is the OODA Loop (Observe, Orient, Decide, Act), developed by Colonel John Boyd. In the context of AI, "Orientation" is the most critical phase. It is where the agent processes raw observations to update its internal model. This is shaped by the system prompt, the content of episodic memory, and context engineering. A flawed orientation leads to hallucinations, causing the agent to diverge from its objective.
In Boyd's theory, the winner of a conflict is the one who can cycle through the OODA loop faster and with higher accuracy. For AI agents, this "Cognitive Maneuverability" translates to the latency and reliability of the inference loop. An agent that can orient itself to a new environment (e.g., a codebase it has never seen) and decide on a correct action within seconds has a massive competitive advantage over traditional, hard-coded software.
The PDCA Cycle and Reliability
While OODA focuses on speed in adversarial environments, the PDCA Cycle (Plan, Do, Check, Act) provides a template for industrial-grade precision. Architectures like "Plan-and-Solve" mimic this by forcing the agent to generate a multi-step roadmap before executing any actions. This ensures auditability and reduces the likelihood of long-horizon errors.
The Cybernetic Definition of Agency
From these foundations, we can derive a technical definition of an AI agent. An agent is not merely an LLM; it is a cybernetic system composed of:
- A Probabilistic Reasoning Core (The LLM): The engine that generates hypotheses and plans.
- A Deterministic Control Loop: The code that manages the flow of execution (the
whileloop). - An Interface to the Environment (Tools): The mechanisms for sensing and acting.
- A Memory Subsystem: The storage of state across time.
This definition highlights that "agency" is an emergent property of the system's architecture, not just the model's intelligence. A smarter model in a broken loop is a chatbot; a weaker model in a robust loop is an agent.
The Anatomy of the Loop
The operational reality of an AI agent is a continuous cycle of four distinct phases.
Sense: The Interface of Perception
Sensing is the transduction of digital state into tokens. This ingestion layer gathers data from the user request, the external environment (web pages, databases, system logs), and the agent's own internal "proprioception" (history).
Effective sensing requires Context Engineering to select the most relevant data. Since LLMs have finite context windows, the system must act as a filter, using techniques like Recursive Summarization or Semantic Retrieval (RAG) to ensure only the most salient tokens reach the model. If the sensing mechanism is noisy, the agent operates in a state of sensory deprivation, leading to "hallucinations" where the model fills in gaps of missing data with plausible but false information.
Think: The Cognitive Core
The "Think" phase is where the LLM processes sensory data into a decision. Unlike standard completion, this output is usually structured JSON representing a plan or tool invocation. Techniques like Chain of Thought (CoT) are essential here, forcing the model to verbalize its reasoning. By making its logic explicit, the system induces a logical progression that is less prone to "intuitive" errors.
Act: The Manifestation of Will
The agent "acts" by issuing tool calls. Modern LLMs are fine-tuned to generate specific structural outputs (typically JSON) that represent these acts.
JSON Schema as Cognitive Scaffolding
In modern agents, tools are defined using JSON Schema. This serves a dual purpose: it is a validation rule for the code, and a semantic prompt for the model. The "Schema is the Prompt" principle states that the description field in a tool's schema is the single most critical factor in tool-use accuracy. A tool named get_data with no description will fail; a tool named get_sales_data with a detailed description of its parameters provides the model with the semantic understanding needed for correct generation.
Validation layers (like Pydantic or Zod) act as a cognitive firewall. They catch invalid parameters before execution and send structured error messages back to the agent ("Error: 'year' must be an integer, received string"), allowing the agent to self-correct in the next turn of the loop.
Observe: Closing the Feedback Loop
Observation is the mechanism of reality testing. The runtime feeds tool results back into the agent's context. This feedback makes the system an "agent" rather than a "script." An agent reads an error message, interprets it as a signal that its mental model was wrong (Orient), and adapts its next plan (Decide/Act) accordingly. This resilience—the ability to recover from execution failure through cognitive adaptation—is the defining characteristic of the loop.
Cognitive Architectures
The "brain" of an agent defines how it plans and reflects.
ReAct: Interleaving Reason and Action
The industry standard, ReAct allows agents to handle unpredictable tool outputs by interleaving "Thought" and "Action" blocks. This "one step at a time" approach is highly adaptable but can suffer from "tunnel vision," where the agent solves local problems while losing track of the global goal.
Plan-and-Execute: The Project Manager
This architecture decouples planning from execution. A "Planner" agent creates a Directed Acyclic Graph (DAG) of tasks, which are then dispatched to "Executor" agents. This is superior for structured, long-horizon tasks like software development, as it prevents the agent from forgetting step 5 while struggling with step 2.
Tree of Thoughts (ToT): Deliberate Search
For problems requiring high-stakes reasoning, ToT introduces algorithmic search into the thinking process, shifting from "System 1" (intuitive generation) to "System 2" (deliberate search) thinking. It treats reasoning as a tree of possibilities:
- Breadth-First Search (BFS): Explores all immediate options to maintain diversity of thought, scoring each "thought" branch before moving deeper.
- Depth-First Search (DFS): Pursues one promising branch until success or failure, then backtracks. This is ideal for logic puzzles like crosswords or math proofs.
Reflexion: Metacognition and Self-Repair
Reflexion grants agents the power of self-improvement by adding a "Reflector" step. If an action fails, the agent generates a verbal critique of why it failed, stores this in episodic memory, and retries the task conditioned on its own critique.
Orchestration Frameworks
Building a raw loop is sufficient for prototypes, but production systems require robust orchestration frameworks that manage state, handle concurrency, and coordinate multiple agents.
| Feature | LangGraph | AutoGen | CrewAI |
|---|---|---|---|
| Core Metaphor | State Machine / Graph | Conversation / Social | Role-playing Team |
| Control Flow | Explicit Edges & Logic | Message Passing | Hierarchical Tasks |
| State Management | Checkpointed (Time Travel) | Conversation History | Task Output Memory |
| Best For | Production apps with strict HITL | Exploratory coding | Rapid prototyping |
LangGraph treats the agent as a cyclic graph, enabling "time travel"—the ability to pause, rewind, and edit an agent's state. AutoGen models agency as social interaction, where agents (Assistant, Coder, UserProxy) solve tasks through dialogue. CrewAI introduces a collaborative "Role-playing" approach, where agents are assigned specific personas and goals, working together to complete a shared mission.
Memory Systems and Context Engineering
An agent's "state" must be managed across time within the constraints of the LLM's context window.
Tiered Memory Management
- Short-Term (Contextual): Immediate conversation history.
- Long-Term (Semantic): Vector databases (Pinecone, Chroma) store embeddings for retrieval by meaning.
- Episodic: Storage of discrete events (actions and outcomes), allowing the agent to recall "I tried this approach yesterday and it failed."
- Procedural: Storage of "skills" or "runbooks"—standardized procedures (e.g., specific SQL schemas) that are retrieved only when a relevant task is recognized.
The Substrate Debate: Files vs. Databases
A critical architectural decision is where to store an agent's memory. Filesystems are simple and transparent, allowing agents to navigate folder structures intuitively. However, Databases are essential for production, offering concurrency (multiple agents writing to memory simultaneously without corruption), auditability, and efficient search.
The "Lost in the Middle" Phenomenon
Research indicates that LLMs prioritize information at the beginning (system prompt) and end (latest query) of the context window. Information buried in the middle is often ignored. This necessitates Context Engineering patterns like:
- Context Bursting: Maintaining a lean context but injecting a massive file for one specific turn.
- Progressive Disclosure: Initially showing only metadata (file names) and only loading content upon explicit request.
The Model Context Protocol (MCP)
Connecting LLMs to diverse data sources has historically required brittle "glue code." The Model Context Protocol (MCP) is an open standard designed to be the "USB-C for AI." It standardizes how resources and tools are exposed, allowing an agent to connect to any MCP-compliant server (PostgreSQL, Slack, Google Drive) without code changes. This reduces the cognitive load on the model by providing a unified interface language for environmental interaction.
Failure Modes and Reliability
The transition to agency introduces new classes of failure that differ from standard software bugs.
- Goal Drift: As the context window fills with tool outputs, the original instruction is "pushed out," and the agent may start optimizing for a sub-task while ignoring the main goal.
- Infinite Loops: An agent encountering a persistent error (e.g., "Permission Denied") might try the same action repeatedly. This "mental rut" can exhaust token budgets rapidly without intervention.
- Hallucination Propagation: In an agent, a hallucination isn't just a factual error; it's a Cascade Failure. If an agent hallucinates that a file exists, its subsequent plans are built on a false reality, leading to confident reports of success for work that was never done.
Human-in-the-Loop (HITL) and Guardrails
For safety-critical actions, autonomy must be suspended.
- Breakpoints: Frameworks allow "interrupts" before high-stakes tools (e.g.,
send_email), requiring human approval. - State Editing: Human operators can edit the agent's thought process or draft outputs before resuming the loop, ensuring the AI's "System 1" speed is tempered by human "System 2" judgment.
Future Horizons: The Path to L5 Autonomy
We are moving from single agents to Lattices of Loops—hierarchical swarms where manager agents orchestrate fleets of specialized workers. We are also seeing the rise of Asynchronous Agency, where agents persist for weeks, "sleeping" while waiting for external events and resuming once fresh data is available.
Just as self-driving cars have levels of autonomy, digital agents are evolving:
- Level 1-2: Chatbots and Copilots (Supportive).
- Level 3: Supervised Agents (Can run tasks but need approval).
- Level 5: Fully Autonomous Systems capable of handling all edge cases in a specific domain.
The AI agent loop has transformed the LLM from a library of frozen knowledge into an active participant in the digital economy. Mastering these mechanics—reasoning, memory, tooling, and orchestration—is the foundation for the next generation of software: systems that do not just compute, but think.
