1. Introduction: The Generative Shift and the Output Constraint
The field of Information Extraction (IE) has undergone a tectonic shift in the last half-decade, transitioning from a discipline dominated by discriminative, supervised pipeline architectures to one centered on generative, general-purpose reasoning engines. Historically, tasks such as Named Entity Recognition (NER), Relation Extraction (RE), and Event Extraction (EE) were approached as sequence labeling problems. Models like BERT or BiLSTM-CRFs would ingest a sequence of text and assign a categorical label to each token. This paradigm was computationally efficient—scaling linearly with input length ($O(N)$)—and output-agnostic; the "output" was merely a set of indices and tags, negligible in size compared to the input.1
However, the advent of Large Language Models (LLMs) like GPT-4, Claude, and Llama has redefined IE as a sequence-to-sequence generation task. In this new paradigm, the model does not merely "tag" text; it synthesizes a structured textual representation (typically JSON, XML, or SQL) of the information contained therein. This shift unlocks unprecedented flexibility, allowing for zero-shot schema adaptation, complex nested extraction, and the normalization of entities without task-specific fine-tuning.3 Yet, it introduces a critical, often underestimated structural vulnerability: the output token limit.
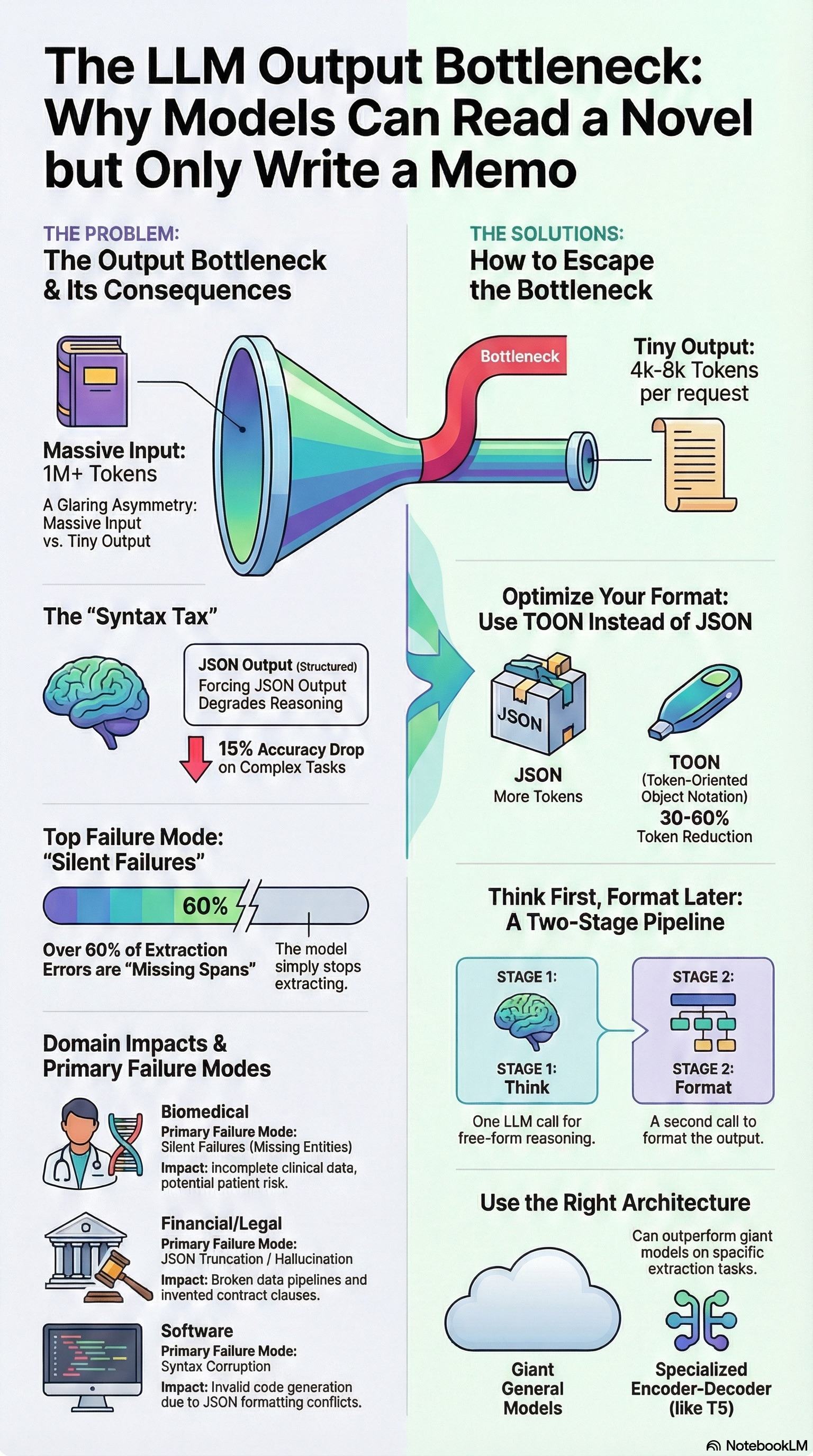
While the input capacities of modern LLMs have expanded aggressively—growing from 4,096 tokens to 128k, 1 million, and even 2 million tokens in architectures like Gemini 1.5 Pro—the output generation capacity has remained remarkably static. Most frontier models impose a hard generation cap, typically between 4,096 and 8,192 tokens per inference call.5 This glaring asymmetry—where a model can "read" a novel but only "write" a short essay—constitutes the primary hurdle for LLM-driven IE in high-density domains.
This report provides an exhaustive analysis of the output token limit as a binding constraint on information extraction. We explore the architectural underpinnings of this bottleneck, rooted in the autoregressive nature of Transformer decoding and the physical limitations of GPU memory bandwidth.7 We examine the "cognitive tax" imposed by output constraints, where the requirement to generate verbose syntax (like JSON) cannibalizes the compute budget available for reasoning, leading to a demonstrable degradation in extraction accuracy.8 Furthermore, we detail the specific failure modes that arise when high-information-density documents collide with these generation ceilings—ranging from syntactic truncation to "silent failures" where models hallucinate completion or omit tail-end data to conserve tokens.10 Finally, we analyze the emerging algorithmic and architectural mitigations, from Token-Oriented Object Notation (TOON) to recursive inference pipelines, that aim to circumvent the tyranny of the output limit.
2. The Architectural Physics of the Output Bottleneck
To comprehend why the output token limit persists as a hurdle despite the massive scaling of input context windows, it is necessary to dissect the underlying mechanics of autoregressive generation. The "hurdle" is not merely an arbitrary API restriction but a reflection of fundamental computational and hardware constraints inherent to the Decoder-only Transformer architecture.
2.1 The Autoregressive Cost Function
In a Decoder-only architecture (e.g., GPT, Llama), generation is a serial process. Unlike the encoding phase, where the attention mechanism processes all input tokens in parallel (allowing for massive prompt ingestion), the decoding phase generates tokens one by one. Each new token requires a full forward pass through the model's layers, attending to all previous tokens (input + generated output).12
This serialization creates a linear latency penalty. If a model generates 100 tokens per second, a 4,000-token extraction payload requires 40 seconds of continuous GPU occupancy. For high-volume IE tasks—such as extracting line-item data from thousands of invoices—this latency becomes operationally prohibitive.13 The cost of generation is thus relative to the output size, whereas discriminative extraction was effectively (constant time relative to the number of entities).
Furthermore, the memory footprint of the Key-Value (KV) cache grows with every generated token. In distributed inference systems serving massive models (e.g., 70B+ parameters), the synchronization overhead required to manage this growing cache across multiple GPU chips becomes a "hidden gatekeeper" of performance. Research indicates that sub-microsecond all-reduce synchronization is essential to exploit memory bandwidth, yet as the sequence length grows, the communication overhead begins to dominate, effectively placing a hardware-imposed ceiling on efficient long-form generation.7
2.2 The "Donut Hole" and Attention Degradation
The "context window" is often marketed as a monolithic capacity (e.g., "128k context"), but functionally, it is a shared buffer for both input and output. The effective capacity for extraction is the total window minus the input. However, simply having space in the buffer does not guarantee performance.
As the generation sequence lengthens, models exhibit the "Lost in the Middle" or "Donut Hole" phenomenon. The attention mechanism fails to maintain uniform fidelity across long sequences, preferentially attending to the beginning (input instructions) and the immediate end (recent generation), while "forgetting" information in the middle.5 In the context of IE, this manifests as a "recall degradation curve."
Consider a 50-page contract where the model is tasked with extracting every obligation. As the JSON output grows to thousands of tokens, the model's ability to attend back to the specific clause on page 25 diminishes. The probability distribution of the next token becomes less sharp ("flatter") as the dependency distance increases. Empirical studies using Information Bottleneck Theory suggest that while LLMs compress input information into specific task spaces (e.g., semantic vectors) during the encoding phase, they struggle to decompress this information effectively during the prediction phase if the output sequence is extensive.17 The bottleneck, therefore, is not just a hard stop implemented by the provider but a functional degradation of coherence and accuracy as the output length pushes against the model's attention span limits.18
2.3 Latency vs. Throughput: The Copy-Heavy Dilemma
A specific subset of IE tasks, often termed "Copy-Heavy" extraction, exacerbates this bottleneck. These tasks involve extracting large verbatim sections of text, such as normalizing a messy bibliography or digitizing a handwritten form. In these scenarios, the model must essentially act as an intelligent copier.
However, because generative models must "predict" every token they copy, the process is incredibly inefficient compared to traditional string operations. A "generation-first" workflow for copy-heavy tasks wastes significant computational budget on text that could be copied in constant time by a non-generative system. This inefficiency leads to a high "Time-to-First-Token" (TTFT) and an even higher "Time-to-Last-Token," making real-time extraction from long documents infeasible for user-facing applications.14 The pressure to reduce latency often leads developers to artificially truncate outputs or limit the scope of extraction, thereby compromising the completeness of the data.
2.4 The Fine-Tuning Length Bias
A more subtle, learned constraint is the "length bias" introduced during Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF). Most SFT datasets consist of concise, helpful answers—summaries, code snippets, or brief explanations. Consequently, models are biased toward brevity.
When tasked with exhaustive information extraction (e.g., "extract every mention of a protein interaction in this 100-page paper"), the model's internal probability distribution favors termination. Even if the context window allows for more tokens, the model tends to output an End-of-Sequence (EOS) token prematurely because it statistically aligns with the shorter completion lengths seen during training.5 This results in "unannotated spans"—a dominant error type where the model simply stops extracting valid entities because it "feels" the answer is long enough.3 This is not a hardware limit but an alignment-induced soft limit that is equally obstructive to comprehensive IE.
3. The Reasoning-Format Trade-off: Constraints vs. Cognition
One of the most critical insights emerging from recent research is the antagonistic relationship between structural constraints (formatting) and cognitive performance (reasoning). In the pursuit of machine-readable IE, practitioners often enforce strict output schemas (e.g., JSON, XML) to ensure the data can be parsed by downstream applications. However, this imposes a "syntax tax" on the model's output budget, which effectively crowds out its reasoning capabilities.
3.1 The "Let Me Speak Freely" Phenomenon
The paper "Let Me Speak Freely? A Study On The Impact Of Format Restrictions On Large Language Model Performance" 8 provides rigorous empirical evidence of this trade-off. The authors investigated how format-restricting instructions (FRI) and constrained decoding (JSON mode) impact a model's ability to perform complex tasks.
The findings are stark:
- Reasoning Degradation: When models are forced to output JSON directly, accuracy on reasoning-heavy tasks (such as mathematical word problems or complex logic deduction) drops by 10% to 50% compared to free-form generation.9
- Mechanism of Interference: The cognitive load of managing syntax (opening braces, ensuring valid keys, closing quotes) competes with the semantic processing required to solve the task. The model is effectively "distracted" by the formatting constraints.
- Key Ordering Issues: In zero-shot settings, models often output the answer key before the reasoning key (e.g., {"answer": "5", "reasoning": "..."}). This prevents the model from utilizing Chain-of-Thought (CoT), as the answer is committed to before the reasoning is generated. This "answer-first" structure forces the model to guess without derivation, leading to significantly lower accuracy.8
This phenomenon is particularly detrimental for "Complex IE" tasks—where extraction requires inference (e.g., "extract the diagnosis implied by this clinical narrative" rather than just "extract the diagnosis explicitly stated"). If the output token limit forces a concise JSON structure, the model loses the token space required to "think" before it extracts, leading to lower F1 scores on implicit entities.21
3.2 Constrained Decoding and Distribution Shift
Constrained decoding (or Grammar-Based Decoding) is a technique used to guarantee that the output adheres to a specific schema (e.g., JSON Schema) by masking invalid tokens at each generation step.24 For example, if the schema expects an integer, the decoder sets the probability of all non-numeric tokens to zero.
While this solves the problem of syntax errors, it introduces a "distribution shift." When the model's preferred token (based on its training) is masked because it violates the schema, the sampler is forced to choose a lower-probability token. This deviation from the optimal path can accumulate, leading to "high-perplexity" extractions where the content is syntactically valid but semantically incorrect or hallucinated.26 Research shows that stricter format constraints lead to greater performance degradation, creating a paradox: tighter schemas yield more reliable parsing but less reliable data extraction.26
3.3 The Chain-of-Thought (CoT) Token Tax
The advent of "reasoning models" (e.g., o1-preview, DeepSeek-R1) introduces a new dimension to the output limit hurdle. These models generate "thinking tokens"—internal monologues used to refine the answer—which count against the output token limit.28
- The Ratio Paradox: As the complexity of the IE task increases, the model requires more thinking tokens to resolve ambiguities. However, these thinking tokens consume the limited buffer available for the actual JSON payload.
- Truncation Risk: If a model spends 3,000 tokens reasoning about a complex legal contract and the output limit is 4,096, it has only 1,096 tokens left to output the extracted entities. If the entity list is long, the JSON will be truncated.29
- Safety vs. Utility: Research by HydroX AI indicates that while longer "thinking" outputs generally improve safety and reasoning, they can reduce the "thinking token ratio" (the proportion of reasoning to final text) if the total generation hits the limit. This can lead to shallower analysis in the final output, as the model "rushes" to conclude before the cutoff.29
The output limit thus forces a zero-sum game: every token spent on reasoning is a token stolen from the extraction payload, and every token reserved for the payload reduces the depth of reasoning available to ensure accuracy.
4. Failure Modes in High-Density Information Extraction
The collision between high-density source documents and the output token limit results in specific, observable failure modes. These are not merely theoretical risks but persistent operational issues in production IE systems.
4.1 JSON Truncation and Syntax Corruption
The most immediate and common failure mode is the physical truncation of the structured object. When extracting from a document containing hundreds of entities (e.g., a list of transactions, a bibliography, or a genetic sequence), the JSON output may exceed the token limit.
- Malformed JSON: The generation stops mid-stream (e.g., {"items": [{"id": 1}, {"id": 2...), rendering the entire object unparsable by standard libraries.10 This essentially wastes the entire inference cost, as the partial data is often trapped in a broken structure.
- Data Loss at the Tail: The entities mentioned late in the source document are systematically omitted. This introduces a "positional bias" in the extracted dataset, where data from the beginning of documents is over-represented while data from the end is ignored. This is particularly dangerous in fields like pharmacovigilance, where adverse events might be listed in an appendix or a final summary table.5
- Correction Costs: Attempting to repair malformed JSON (using "healing" parsers or secondary LLM calls) adds significant latency and cost, and often cannot recover the missing data that was never generated.11
4.2 Hallucination in Long-Tail Generation
As the generation progresses and the context window fills, models are more prone to hallucination. In high-density extraction, models may start inventing entities to "complete" a pattern or fill a schema requirement, especially when the "Donut Hole" effect causes them to lose track of the source text.11
- Repetition Loops: Approaching the token limit often triggers repetitive behavior, where the model outputs the same entity multiple times or gets stuck in a loop of opening and closing brackets. This is a known artifact of the sampling strategies used in Transformers when probability distributions flatten.27
- Schema Drift: In very long outputs, the model may "forget" the strict constraints of the schema. It might start strictly adhering to the JSON structure but, after 2,000 tokens, drift into free text, Markdown, or a hybrid format ("...and 5 more items"), invalidating the extraction pipeline.11 This "Schema Drift" is a direct consequence of the loss of coherence over long generation sequences.33
4.3 The "Silent Failure" of Missing Spans
Perhaps the most insidious failure mode is the "silent failure," where the model produces valid JSON but omits a significant portion of the entities due to the internal biases discussed earlier.
- Unannotated Spans: Evaluation of GPT-4 on IE tasks reveals that "Missing spans" and "Unannotated spans" are the dominant error types, accounting for over 60% of errors.3 The model simply stops extracting after a certain point, effectively "giving up" to conserve tokens, even if the output limit hasn't been strictly hit. This is often indistinguishable from a correct extraction of a sparse document, making it difficult to detect without manual audit.
- Recall Degradation: In "Needle-in-a-Haystack" tests modified for extraction (finding multiple needles), recall drops significantly as the number of needles (target entities) increases. This is primarily because the output generation burden exceeds the model's coherence span.16
5. Benchmarking the Hurdle: Evidence from Long-Context Evaluations
To quantify the magnitude of these hurdles, the research community has developed specialized benchmarks that stress-test LLMs on long-context and high-output tasks. These benchmarks provide the empirical data necessary to understand the severity of the token limit constraint.
5.1 LongBench and LongBench v2
LongBench v2 introduces a specific category for "Long Structured Data Understanding," recognizing the unique challenge of extracting tabular or JSON data from long contexts.34 This benchmark is pivotal because it moves beyond simple retrieval ("find the needle") to complex synthesis ("extract the table").
- The Performance Gap: Human experts achieve approximately 53.7% accuracy on these tasks (within a time limit), while the best models (direct answer) achieve only 50.1%. The "Long Structured Data" category shows the largest gap between human and model performance compared to other tasks like summarization or QA. This highlights that models struggle to maintain structural integrity and semantic accuracy over long extraction sequences.37
- Reasoning vs. Extraction: The benchmark reveals that reasoning-enhanced models like o1-preview perform better (57.7%) but require significantly more tokens. This reinforces the "token tax" theory: better performance is possible, but it comes at the cost of consuming the output budget, which limits the scale of extraction possible in a single pass.28
5.2 ZeroSCROLLS and Aggregation Tasks
The ZeroSCROLLS benchmark includes "Aggregation" tasks (e.g., SpaceDigest, BookSumSort) that require synthesizing information from the entire document into a single output.38
- The Aggregation Bottleneck: These tasks are particularly punishing for output token limits because the result is not a single answer but a summary or list derived from the whole text (e.g., "percentage of positive reviews across 50 reviews"). Models struggle to pass the naive baseline on these tasks, indicating a failure to maintain the "global state" required to generate the full output.40
- Zero-Shot Struggles: In zero-shot settings, without the guidance of fine-tuning, models often fail to adhere to the output format or truncate the aggregation. This leads to extremely low scores on metrics like "Exponential Similarity," which penalize incomplete or malformed outputs.42
5.3 Hardware and Quantization Trade-offs
Research into model optimization reveals that hardware constraints further enforce the output limit. Quantization (e.g., using 4-bit GPTQ) is a common technique to fit large models into limited VRAM. However, this paradoxically slows down inference due to dequantization overhead.
- Latency Impact: In one study, 4-bit quantization reduced VRAM usage by 41% but slowed inference by 82% on NVIDIA T4 GPUs.43 This drastic increase in latency makes the "time-per-token" cost of long JSON generation even higher, pushing developers to cap output lengths not just for quality reasons, but to prevent timeouts in production systems.
- Memory Bandwidth: The study "LLM Inference Memory-bandwidth And Latency" (LIMINAL) establishes that memory bandwidth is the hard limit for decoding throughput. High-volume extraction requires hundreds of GB/s of bandwidth per user. If the output length is large, the system becomes memory-bound, and the throughput collapses, making long-form extraction economically unviable at scale.7
6. Algorithmic and Structural Mitigations
Faced with these physical and architectural limits, the field has evolved a set of mitigation strategies. These range from simple prompt engineering hacks to fundamental re-architectures of the extraction pipeline.
6.1 Chunking and Recursive Extraction
The most common workaround is splitting the input document into chunks that fit comfortably within the context window, extracting information from each chunk, and then aggregating the results. This transforms a single long-context problem into multiple short-context problems.31
- Recursive Summarization: This method involves summarizing chunks and then summarizing the summaries. While effective for general content, it carries high risk for IE. Specific entities (e.g., a specific transaction ID) are often lost in the compression steps as the model prioritizes high-level themes over granular data.46
- Intelligent Chunking: To preserve context, overlapping chunks are used. However, this introduces the problem of Entity Duplication (the same entity extracted from two overlapping chunks) and Context Fragmentation (relationships spanning a chunk boundary are lost). Resolving these duplicates (Entity Resolution) becomes a secondary, complex NLP task.45
- Map-Reduce Pipelines: Frameworks like LangChain allow for "Map" (extract from chunk) and "Reduce" (merge JSONs) operations. This solves the token limit but increases API costs and latency linearly with document length. It effectively trades tokens for time and money.31
6.2 Token-Optimized Formats (TOON vs. JSON)
Recognizing that JSON is "token-expensive" due to repeated keys and syntax (braces, quotes), a new wave of research focuses on optimizing the output format itself. If the limit is 4,000 tokens, making the data denser allows more information to fit in the same window.
- TOON (Token-Oriented Object Notation): A format designed specifically for LLMs that uses a header-row style (similar to CSV but structured) to define keys once. Benchmarks show TOON reduces token usage by 30-60% compared to JSON while maintaining or even improving accuracy.48 By removing the redundancy of repeating {"name": "...", "id": "..."} for every item, TOON allows the model to extract significantly more entities before hitting the limit.
- Comparison with YAML and CSV:
- JSON: High token usage, high structural clarity. Best for complex nesting.
- YAML: Medium token usage, reliant on indentation. Can be fragile if the model miscounts spaces.
- CSV: Lowest token usage for flat data, but cannot represent nested structures (e.g., addresses within users).
- TOON: The "Goldilocks" solution for LLMs—low token count, supports basic nesting, and uses explicit headers to guide the model.51
The adoption of TOON or similar concise formats is a direct response to the output token hurdle, acting as a "compression algorithm" for the generation phase.
6.3 Two-Stage Inference: "Think First, Format Later"
To address the "Let Me Speak Freely" trade-off (where formatting hurts reasoning), a two-stage pipeline is increasingly adopted.21
- Stage 1 (Reasoning): The model is prompted to analyze the text and extract information in a free-form, unstructured manner (Chain-of-Thought). This utilizes the "thinking tokens" effectively without the overhead of JSON syntax. The model "speaks freely" to establish the facts.
- Stage 2 (Formatting): A second, often cheaper/faster model (or a constrained decoding step) takes the free-form output and converts it into valid JSON.
- Benefits: This approach separates the cognitive load of extraction from the syntactic load of formatting. It yields higher accuracy on complex reasoning tasks (jumping from 48% to 61% in some benchmarks) because the model is not fighting the syntax while trying to understand the text.21
- Costs: It doubles the number of inference calls (though the second call is usually short). It essentially pays a "latency tax" to bypass the "reasoning tax."
6.4 Recursive Language Models (RLMs)
A more advanced architectural solution is the Recursive Language Model, which can spawn sub-calls to itself to handle different parts of the context. Instead of generating one giant output, the root LM generates queries or code to retrieve specific data points, effectively managing the context via an external "environment" (REPL).53
In this paradigm, the "output" is not the final extracted data but a program or a query that fetches the data. This moves the state management from the output buffer (which is limited) to an external system (which is unlimited), bypassing the single-call token limit entirely. The model becomes an orchestrator rather than just a generator.
6.5 Generative Feedback Loops and Self-Correction
To combat silent failures and truncation, systems employ feedback loops where a "Verifier" LLM checks the output of the "Extractor" LLM against the schema and source text. If the output is truncated or missing keys, the Verifier prompts the Extractor to "continue" or "fix" the output.13
- Iterative Refinement: This approach converges toward higher accuracy but significantly increases the "Time-to-Extraction" and cost. It transforms the extraction process into a conversation, where the "hurdle" is overcome by simply taking multiple jumps.54
7. Comparative Analysis of Architectures: Encoder-Decoder vs. Decoder-Only
The current dominance of Decoder-Only models (GPT, Llama) has obscured the potential benefits of Encoder-Decoder architectures (T5, BART) for IE tasks, particularly regarding output efficiency.
7.1 The Decoder-Only Bottleneck
Decoder-Only models must regenerate the attention matrix for the entire sequence (input + output so far) for every new token. While KV caching mitigates the re-computation, the memory bandwidth requirement grows linearly with the sequence length. This makes generating long outputs computationally expensive and prone to "latency degradation".12 Furthermore, because they are trained for open-ended generation, they are architecturally predisposed to "wander" or hallucinate when forced to produce long, rigid structures.
7.2 The Encoder-Decoder Advantage
Encoder-Decoder models (like T5) process the input once (Encoder) and then generate the output (Decoder). This architecture naturally separates "understanding" from "generation."
- Efficiency: For tasks where the output is much shorter than the input (e.g., summarization or sparse extraction), Encoder-Decoder models are often more efficient. They compress the input into a dense latent representation, allowing the decoder to work solely on generation without constantly re-attending to the raw input tokens in the same way.55
- Bi-directionality: The encoder uses bi-directional attention (seeing the whole document at once), which arguably creates a more robust representation for extraction than the uni-directional (left-to-right) attention of decoder-only models. This global view is crucial for resolving dependencies that span the entire document.56
- Performance: Benchmarks suggest that while Decoder-Only models are better at zero-shot generalization, fine-tuned Encoder-Decoder models often outperform them on specific IE tasks with lower computational overhead. A fine-tuned T5 model can often match the extraction performance of a much larger GPT model while being orders of magnitude faster to inference, effectively mitigating the latency aspect of the output hurdle.55
8. Domain-Specific Implications
The impact of the output token limit is not uniform; it varies significantly across domains, dictated by the density of the information and the tolerance for error.
8.1 Biomedical and Clinical Extraction
In clinical IE (e.g., extracting symptoms, medications, and dosages from discharge summaries), the cost of truncation is critical. A missing "dosage" or "frequency" due to a token limit cut-off can render the extraction dangerous.57
- Zero-Shot Performance: Models like Llama-3.3-70B show strong zero-shot capabilities but are hindered by token-level output formats for NER. The high density of medical terms often leads to output limits being hit quickly. A single discharge summary might contain hundreds of clinical concepts.58
- Entity Density: Medical papers are "dense"—a single paragraph may contain dozens of relevant entities (proteins, genes, interactions). Extracting all of them often requires a multi-pass approach because a single pass hits the token limit. Research confirms that LLMs struggle with "complex efficacy and adverse event data," often achieving low F1 scores (0.22-0.50) due to the sheer volume of details required.59
8.2 Financial and Legal Document Processing
These domains involve long documents (contracts, 10-K reports) with strict schema requirements and zero tolerance for hallucination.
- Schema Complexity: A financial schema might require nested objects (Company -> Quarter -> Metric -> Value). This nesting explodes the token count. "Let Me Speak Freely" findings are particularly relevant here; forcing a strict XBRL-like JSON structure often degrades the model's ability to interpret complex financial footnotes.8
- Table Extraction: Extracting tables from PDFs into JSON is a "Copy-Heavy" task. The latency of generating thousands of table cell tokens sequentially is a major bottleneck. Enterprise solutions often revert to hybrid approaches (OCR for structure + LLM for interpretation) rather than pure LLM generation to avoid the "generation-first" latency penalty.14
8.3 Coding and Repository Analysis
Extracting function signatures, dependencies, or class hierarchies from codebases represents an extreme version of the output hurdle.
- Repo-Level Extraction: Tasks in LongBench involving repository understanding require the model to output valid code or structured metadata about code. The strict syntax of programming languages (where a missing semicolon breaks everything) combined with the length of the output makes this one of the hardest categories for current LLMs.36
- JSON-Wrapping Code: Benchmarks show that asking models to wrap code in JSON (e.g., {"code": "def function()..."}) significantly increases syntax errors in the code itself. The model struggles to manage the escaping of characters (like quotes and backslashes) within the JSON string, leading to broken code and broken JSON.60
9. Conclusion
The output token limit acts as a fundamental physical and cognitive constraint on LLM-driven Information Extraction. It creates a critical bottleneck that is distinct from, and often more limiting than, the input context capacity. While models can now "read" entire libraries, they can still only "write" a few pages at a time. This asymmetry forces a compromise: practitioners must choose between the depth of reasoning (using tokens for Chain-of-Thought) and the breadth of extraction (using tokens for JSON payload).
The mechanisms of this hurdle are deeply rooted in the autoregressive architecture of modern Transformers—specifically the computational cost of serial generation ($O(N)$), the degradation of attention in long sequences (Donut Hole), and the distribution shifts introduced by constrained decoding. The "Let Me Speak Freely" phenomenon highlights that the tight coupling of formatting and reasoning is detrimental, suggesting that the future of IE lies in decoupled architectures where "thinking" and "formatting" are handled by distinct processes.
Overcoming this hurdle requires a shift from "brute force" generation to "architectural elegance." Strategies such as Token-Oriented Object Notation (TOON), Recursive Language Models, and Two-Stage Inference (Reason then Format) offer pathways to maximize the utility of the limited output window. Furthermore, a resurgence of interest in Encoder-Decoder architectures for specific extraction tasks suggests that the "One Model to Rule Them All" approach may give way to specialized pipelines where efficient, fine-tuned models handle the high-volume generation that generalist LLMs struggle to sustain.
Ultimately, solving the output token bottleneck is not just about increasing max_tokens; it is about redesigning the interaction between the model's cognitive process and its communicative output, ensuring that the constraints of the format do not strangle the intelligence of the extraction.
---
Table 1: Comparison of Output Formats for LLM Extraction
| Feature | JSON (Pretty) | JSON (Compact) | YAML | TOON | Implication for Output Limit |
|---|---|---|---|---|---|
| Token Usage | High (Baseline) | Medium (~85%) | Medium-Low (~95%) | Low (40-60%) | TOON allows ~2x more entities per inference call before hitting the limit. 51 |
| Schema Explicit? | No (Repeated Keys) | No (Repeated Keys) | No (Repeated Keys) | Yes (Header Row) | Explicit headers reduce hallucination of keys and enforce structure. 49 |
| Nesting Support | Excellent | Excellent | Good | Limited/Complex | TOON struggles with deep nesting; JSON is better for complex schemas. |
| LLM Accuracy | High | High | Good | High (>70%) | TOON shows improved accuracy in retrieval tasks due to reduced noise. 49 |
| Parsing Reliability | High (Standard Libs) | High | Medium (Indentation) | Medium (Custom) | JSON is safer for downstream integration; TOON requires custom converters. |
Table 2: Impact of Constraints on Reasoning (from "Let Me Speak Freely"
| Task Type | Free-Form Generation | Constrained JSON Mode | Performance Delta | Reasoning Implication |
|---|---|---|---|---|
| Math Reasoning | 85% Accuracy | 70% Accuracy | -15% | Formatting tax significantly reduces cognitive capacity for calculation. |
| Symbolic Logic | 60% Accuracy | 45% Accuracy | -15% | Model prioritizes syntax validity over logical consistency. |
| Classification | 90% Accuracy | 92% Accuracy | +2% | Constraints help narrow the search space for simple, non-reasoning tasks. |
| Aggregation | 54.4% Accuracy | 48.8% Accuracy | -5.6% | 21 Aggregation requires global context maintenance, which constraints disrupt. |
Table 3: Failure Modes by Domain
| Domain | Primary Failure Mode | Cause | Impact |
|---|---|---|---|
| Biomedical | Silent Failure (Unannotated Spans) | High density of entities vs. length bias. | Incomplete clinical data; potential patient risk. 57 |
| Financial | JSON Truncation | Long tables/lists exceed output cap. | Broken pipelines; loss of tail-end fiscal data. 14 |
| Legal | Hallucination/Drift | "Donut Hole" in long contract review. | Invented clauses; schema drift into free text. 11 |
| Software | Syntax Corruption | JSON escaping interferes with Code syntax. | Invalid code generation; unparsable JSON. 60 |
Works cited
- Information Extraction in Low-Resource Scenarios: Survey and Perspective - arXiv, accessed January 15, 2026.
- Information Extraction in Low-Resource Scenarios: Survey and Perspective - arXiv, accessed January 15, 2026.
- An Empirical Study on Information Extraction using Large Language Models - arXiv, accessed January 15, 2026.
- Distilling Large Language Models into Tiny Models for Named Entity Recognition - arXiv, accessed January 15, 2026.
- Why Do LLMs Truncate Their Outputs? - Medium, accessed January 15, 2026.
- Why do llms have output limit? - Reddit, accessed January 15, 2026.
- Efficient LLM Inference: Bandwidth, Compute, Synchronization, and Capacity are all you need - arXiv, accessed January 15, 2026.
- Let Me Speak Freely? A Study On The Impact Of Format Restrictions On Large Language Model Performance - Liner, accessed January 15, 2026.
- Let Me Speak Freely? A Study On The Impact Of Format Restrictions On Large Language Model Performance - ACL Anthology, accessed January 15, 2026.
- Handling LLM output and truncation in workflows - n8n Community, accessed January 15, 2026.
- Here's everything that goes wrong when AI does text extraction (and how we're still using it) - OpenSanctions, accessed January 15, 2026.
- Encoder-Decoder vs. Decoder-Only. What is the difference between an… - Medium, accessed January 15, 2026.
- Challenges in Structured Document Data Extraction at Scale with LLMs - Zilliz blog, accessed January 15, 2026.
- Hybrid OCR-LLM Framework for Enterprise-Scale Document Information Extraction Under Copy-heavy Task - arXiv, accessed January 15, 2026.
- Understanding Communication Bottlenecks in Multi-node LLM Inference - SC25, accessed January 15, 2026.
- Assessing the quality of information extraction - arXiv, accessed January 15, 2026.
- Exploring Information Processing in Large Language Models: Insights from Information Bottleneck Theory - arXiv, accessed January 15, 2026.
- LongGenBench: Benchmarking Long-Form Generation in Long Context LLMs - OpenReview, accessed January 15, 2026.
- PARSE: LLM Driven Schema Optimization for Reliable Entity Extraction - arXiv, accessed January 15, 2026.
- [Literature Review] Let Me Speak Freely? A Study on the Impact of Format Restrictions on Performance of Large Language Models - Moonlight, accessed January 15, 2026.
- Beyond JSON: Picking the Right Format for LLM Pipelines - Medium, accessed January 15, 2026.
- Let Me Speak Freely? A Study on the Impact of Format Restrictions on Performance of Large Language Models - GitHub, accessed January 15, 2026.
- Zhi-Rui Tam - ACL Anthology, accessed January 15, 2026.
- Generating Structured Outputs from Language Models: Benchmark and Studies - arXiv, accessed January 15, 2026.
- JSONSchemaBench: Evaluating Constrained Decoding with LLMs on Efficiency, Coverage and Quality - OpenReview, accessed January 15, 2026.
- Computational Complexity of Schema-Guided Document Extraction - Pulse AI, accessed January 15, 2026.
- Let Me Speak Freely? A Study On The Impact Of Format Restrictions On Large Language Model Performance - ResearchGate, accessed January 15, 2026.
- LongBench v2 - accessed January 15, 2026.
- New Research: Exploring the Impact of Output Length on LLM Safety - HydroX AI, accessed January 15, 2026.
- Data extraction: The many ways to get LLMs to spit JSON content - Guillaume Laforge, accessed January 15, 2026.
- How to Process Huge Documents with LLMs? - Eden AI, accessed January 15, 2026.
- Comparative Evaluation of GPT-4o, GPT-OSS-120B and Llama-3.1-8B-Instruct Language Models in a Reproducible CV-to-JSON Extraction Pipeline - MDPI, accessed January 15, 2026.
- LLM-empowered knowledge graph construction: A survey - arXiv, accessed January 15, 2026.
- Problem Solved? Information Extraction Design ... - ACL Anthology, accessed January 15, 2026.
- LongBench Pro: A More Realistic and Comprehensive Bilingual Long-Context Evaluation Benchmark - arXiv, accessed January 15, 2026.
- LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks - ACL Anthology, accessed January 15, 2026.
- LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks - Liner, accessed January 15, 2026.
- ZeroSCROLLS: A Zero-Shot Benchmark for Long Text Understanding - Semantic Scholar, accessed January 15, 2026.
- AcademicEval: Live Long-Context LLM Benchmark - arXiv, accessed January 15, 2026.
- ZeroSCROLLS: A Zero-Shot Benchmark for Long Text Understanding - arXiv, accessed January 15, 2026.
- ZeroSCROLLS: A Zero-Shot Benchmark for Long Text Understanding - Tel Aviv University, accessed January 15, 2026.
- [Quick Review] ZeroSCROLLS: A Zero-Shot Benchmark for Long Text Understanding - Liner, accessed January 15, 2026.
- Performance Trade-offs of Optimizing Small Language Models for E-Commerce - arXiv, accessed January 15, 2026.
- Performance Trade-offs of Optimizing Small Language Models for E-Commerce - ResearchGate, accessed January 15, 2026.
- How intelligent chunking makes LLMs better at extracting long documents - Unstract, accessed January 15, 2026.
- AI Summarization of Long Documents: Tackling Long Documents with Precision - Codesphere, accessed January 15, 2026.
- Advanced multiple document summarization via iterative recursive transformer networks and multimodal transformer - PMC, accessed January 15, 2026.
- Is JSON Outdated? The Reasons Why the New LLM-Era Format "TOON" Saves Tokens - Dev.to, accessed January 15, 2026.
- From JSON to TOON: Evolving Serialization for LLMs - Towards AI, accessed January 15, 2026.
- JSON vs TOON: Which Output Format Is Best for Generative AI Applications? - Dev.to, accessed January 15, 2026.
- How to use TOON to reduce your token usage by 60% - LogRocket Blog, accessed January 15, 2026.
- JSON vs TOON: Choosing the Right Data Format for the AI Era - Medium, accessed January 15, 2026.
- Recursive Language Models - Alex L. Zhang, accessed January 15, 2026.
- Dual-LLM Adversarial Framework for Information Extraction from Research Literature - bioRxiv, accessed January 15, 2026.
- A Primer on Decoder-Only vs Encoder-Decoder Models for AI Translation - Slator, accessed January 15, 2026.
- Guide to BART (Bidirectional & Autoregressive Transformer) - Analytics Vidhya, accessed January 15, 2026.
- Can You Trust Real-World Data Extracted by a Large Language Model (LLM)? - Flatiron, accessed January 15, 2026.
- Leveraging open-source large language models for clinical information extraction in resource-constrained settings - Oxford Academic, accessed January 15, 2026.
- Harnessing Large‐Language Models for Efficient Data Extraction in Systematic Reviews: The Role of Prompt Engineering - PubMed Central, accessed January 15, 2026.
- LLMs are bad at returning code in JSON - Aider, accessed January 15, 2026.
