The semiconductor industry in 2025 sits at a pivotal inflection point, characterized not merely by the pursuit of Moore's Law, but by a fundamental schism in the nature of artificial intelligence workloads. For the better part of a decade, the "training" of massive neural networks dictated hardware design—monolithic chips, massive floating-point throughput, and unified memory architectures were the gold standard.
However, the maturation of Generative AI into "Agentic AI" and "System 2" reasoning models has forced a bifurcation of the market. We are no longer witnessing a singular race for the fastest GPU; rather, we are observing a diverging war between systems optimized for massive-scale training and emerging architectures designed specifically for the latency-sensitive, memory-bound demands of inference.
Market at a Glance
For those looking for a quick summary of the 2025 landscape, here is the state of play:
| Player | Strategy | Key Hardware | Best Use Case |
|---|---|---|---|
| NVIDIA | System-Level Dominance | Blackwell B200/B300, NVL72 | Frontier Model Training |
| Architectural Efficiency | TPU v6 Trillium, v7 Ironwood | JAX/TensorFlow Workloads | |
| AMD | Memory Capacity Leader | Instinct MI355X (288GB) | High-Throughput Inference |
| AWS | Vertical Integration | Trainium 3 | Cost-Effective Cloud Training |
| Cerebras | Wafer-Scale Speed | WSE-3 | Ultra-Low Latency Agents |
| Groq | Deterministic Speed | LPU | Real-Time Token Generation |
| Intel | Value & Open Systems | Gaudi 3, Jaguar Shores | Cost-Sensitive Enterprise |
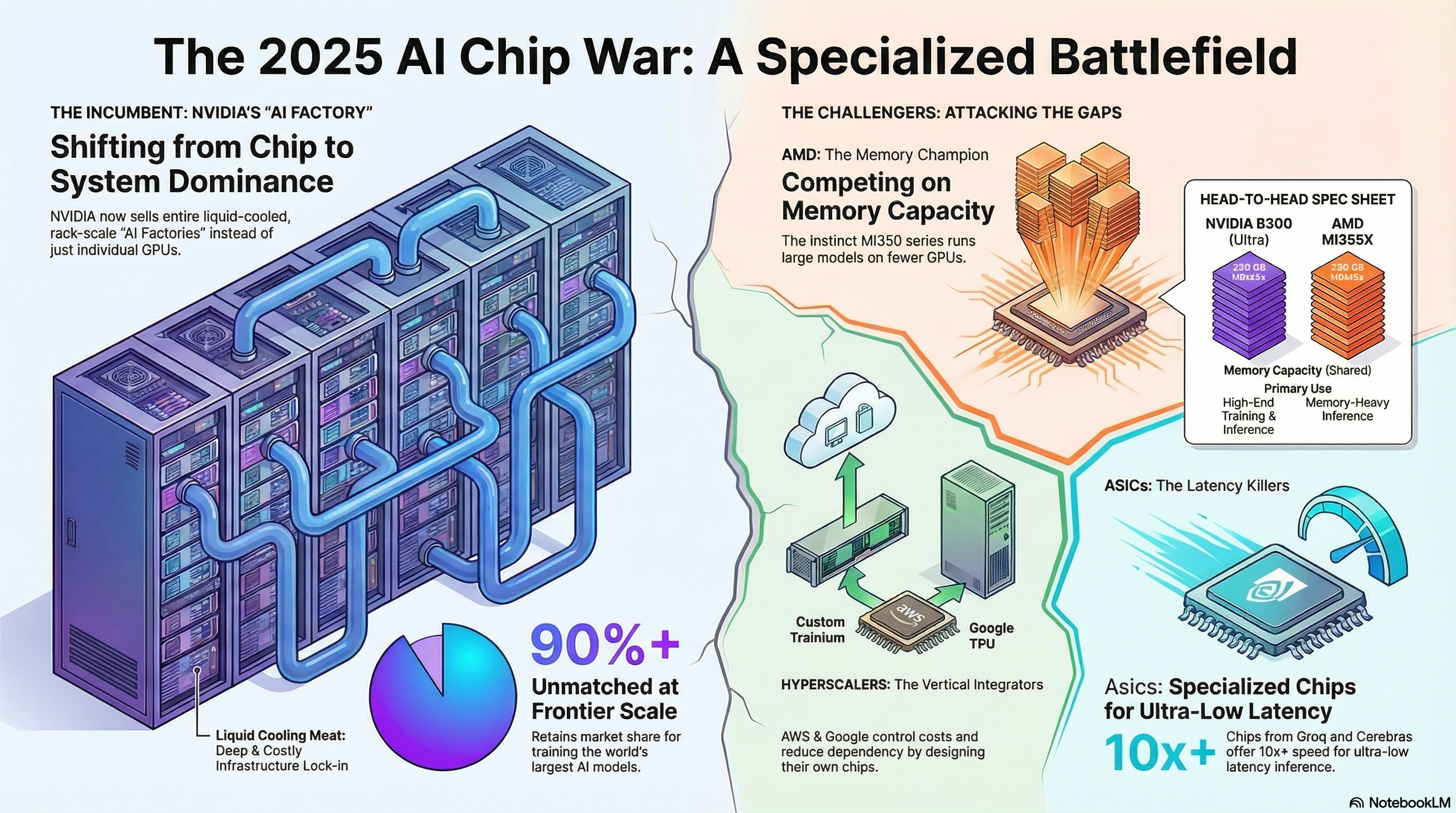
1. The Incumbent Hegemony: NVIDIA’s System-Level Dominance
In 2025, NVIDIA remains the axis around which the AI industry revolves. However, their strategy has fundamentally shifted from chip-level performance to data center-level throughput. With the release of the Blackwell architecture, NVIDIA has effectively declared that the "chip" is obsolete, replaced by the "Superchip" and the liquid-cooled "AI Factory."
The Blackwell Architecture: B200 and B300 Ultra
The Blackwell B200 and its late-2025 successor, the B300 (Blackwell Ultra), represent a departure from the single-die limits of the Hopper generation. By utilizing a multi-die architecture connected via a 10 TB/s high-bandwidth interface (NV-HBI), NVIDIA has created a unified processor that defies traditional lithographic boundaries.
Technical Specifications: The B300 Blackwell Ultra is a critical mid-cycle refresh driven by the voracious memory appetite of "Reasoning" models. These models, utilizing Chain-of-Thought (CoT) processing, require maintaining massive Key-Value (KV) caches. NVIDIA addressed this by upgrading HBM3e memory stacks to twelve-high (12S), boosting capacity to 288 GB per GPU. This 50% increase over the B200 allows models like Llama 3.1 405B to fit on fewer GPUs, reducing the latency-inducing communication overhead between chips.
The FP4 Precision Shift: A defining characteristic of Blackwell is native FP4 support. The B300 delivers 15 PFLOPS of dense FP4 compute, allowing for a theoretical doubling of throughput for inference where slight quantization is acceptable. Supported by the second-generation Transformer Engine, this effectively creates a "virtual" performance boost, doubling the effective batch size of inference servers without hardware upgrades.
The Unit of Compute: GB200 NVL72
NVIDIA’s strategic pivot is the "AI Factory," epitomized by the GB200 NVL72. This is not a collection of servers but a single rack-scale computer combining 36 Grace CPUs and 72 Blackwell GPUs. Connected via a copper backplane, the entire rack acts as a single GPU with 72 dies, delivering up to 1.4 exaFLOPS of AI compute.
Thermal Engineering as a Moat: The NVL72 erects a formidable infrastructure moat. With power density exceeding 120kW per rack, it requires Direct-to-Chip (DTC) liquid cooling. This forces data centers to rebuild facilities to accommodate NVIDIA's plumbing, creating "infrastructure lock-in" far more durable than software.
Future Horizons: Rubin and Jetson Thor
Looking to 2026, the Rubin (R100) architecture will utilize HBM4 to address the memory wall. Meanwhile, NVIDIA is targeting robotics with Jetson Thor, an SoC delivering 2,070 TFLOPS of FP4 performance, paired with "Project GR00T" foundation models to power humanoid robots.
2. The Hyperscaler Revolution: Vertical Integration
The most significant threat to merchant silicon providers comes from their largest customers. AWS, Google, and Microsoft have accelerated custom silicon roadmaps to control margins and supply chains.
Google Cloud: TPU v6 and v7
Google’s Tensor Processing Unit remains the gold standard for alternative architectures.
- TPU v6 (Trillium): The workhorse for Gemini training, offering 4.7x the performance of v5e.
- TPU v7 (Ironwood): Expected late 2025, this is the first TPU explicitly architected for inference, utilizing high-bandwidth interfaces to specialized memory pools for "Agentic" workloads.
- OpenXLA: Google backs the OpenXLA ecosystem, creating a portability layer that reduces vendor lock-in.
Amazon Web Services (AWS): Trainium 3
Trainium 3 represents the first 3nm cloud AI chip, offering a 4x compute increase over Trainium 2 and 40% better energy efficiency.
- UltraServer: Connects 64 to 144 chips in a mesh using NeuronLink, a proprietary interconnect mirroring NVLink.
- Economics: AWS incentivizes adoption through "Savings Plans," making Trainium significantly cheaper than Nvidia instances for heavy users like Anthropic.
Microsoft Azure: Maia 100
Maia 100 is optimized specifically for GPT architectures with 64 GB HBM2e. While memory capacity is lower, it is designed to run specific partitioned shards of GPT-4/5, optimizing for utilization. Like NVIDIA, Microsoft is investing in custom liquid cooling "sidekicks" for Maia racks.
3. The Primary Challenger: AMD’s Open Ecosystem
Advanced Micro Devices (AMD) has successfully pivoted from a value-alternative to a technology leader in memory capacity. The 2025 lineup—MI325X, MI350, and MI355X—executes a strategy of "More Memory, Open Software."
Instinct MI350 Series: CDNA 4 Architecture
The MI350 series is AMD's direct answer to Blackwell, fabricated on a 3nm process.
- Memory Monster: The flagship MI355X features 288 GB of HBM3e, matching the B300 Ultra.
- Performance: AMD claims a 35x leap in inference performance over CDNA 3, driven by native support for FP4 and FP6.
- Strategic Advantage: AMD allows operators to run larger models on fewer GPUs. Fitting a 405B parameter model might require three H100s but only two MI355X chips.
ROCm 7.0: Closing the Software Gap
2025 marks the release of ROCm 7.0, designed for parity with CUDA in PyTorch environments. It supports PyTorch 2.7 out of the box and includes optimizations for vLLM, PagedAttention, and FlashAttention-2. Hyperscalers like Oracle and Microsoft Azure are now deploying MI300X/MI350 instances specifically for memory-bound inference workloads.
Edge and FPGA: Versal AI Edge Gen 2
Leveraging its Xilinx acquisition, AMD’s Versal AI Edge Series Gen 2 combines FPGA programmability with AI engines. Ideal for automotive (LiDAR/Radar) and industrial aerospace, it handles raw sensor pre-processing on FPGA logic before passing clean data to the AI engine.
4. Intel: The Strategic Pivot
Intel in 2025 finds itself in a defensive posture. The cancellation of the Falcon Shores GPU marked a formal retreat from the head-to-head battle with NVIDIA's flagship chips.
- Jaguar Shores: Intel has pivoted to this rack-scale system specification, attempting to sell a complete solution of networking, CPU (Xeon 6), and acceleration, mirroring the NVL72 concept.
- Gaudi 3: Marketed as a value play, Gaudi 3 competes on TCO rather than raw performance. It has found a home with IBM Cloud and second-tier providers for cost-sensitive inference.
5. The Specialized ASIC & Inference Frontier
As AI models shift to "System 2" reasoning, inference requires low latency for complex, multi-step workflows. This has opened the door for "Alt-Silicon."
Cerebras Systems: Wafer-Scale Engine 3 (WSE-3)
Cerebras contests the idea of chiplets with the WSE-3, a single wafer-sized processor with 4 trillion transistors and 900,000 AI cores.
- SRAM Advantage: By keeping models in 44 GB of on-chip SRAM, Cerebras achieves memory bandwidths of 21 PB/s.
- Speed: It generates 2,000+ tokens/second for Llama 70B, a 21x speed advantage over B200 for specific reasoning tasks.
Groq: The Language Processing Unit (LPU)
Groq uses a deterministic, compiler-first architecture with no caches or branch prediction.
- Speed: Unmatched time-to-first-token and throughput for models that fit.
- Challenge: Relying on SRAM (~230 MB per chip) requires huge racks to fit large models. Groq is transitioning to 4nm nodes in 2025 to improve density.
Etched, SambaNova, and Tenstorrent
- Etched: Their "Sohu" chip is hard-coded for Transformers, claiming one server can replace 160 H100s. It's a high-risk, high-reward bet on the longevity of the Transformer architecture.
- SambaNova: The SN40L features a reconfigurable dataflow architecture with a massive three-tier memory system (SRAM, HBM, DDR), enabling training of 5-trillion parameter models.
- Tenstorrent: Led by Jim Keller, their Blackhole and Wormhole chips use a grid of RISC-V cores. Their "QuietBox" targets developers wanting high-performance compute at their deskside.
6. Edge AI & The Mobile Landscape
Qualcomm: Hybrid AI
Qualcomm pushes "Hybrid AI" to balance cloud and device.
- Cloud AI 100 Ultra: A low-power (150W) inference card for the "Edge Cloud" (5G base stations).
- Snapdragon X Elite: Features NPUs capable of running 10B+ parameter models locally, offloading "easy" inference from the cloud.
Hailo: Vision at the Edge
Hailo-15 integrates AI vision processing into the camera ISP pipeline. Capable of 20 TOPS, it enables smart city cameras to perform analytics without sending video streams to a central server.
7. Software Ecosystem Wars
Hardware excellence is irrelevant without software usability. 2025 is the year the CUDA moat faces serious erosion.
- CUDA 13: NVIDIA introduces "CUDA Tile" programming to keep Python developers in their walled garden.
- PyTorch 2.0 & Triton: The industry standard has coalesced around PyTorch 2.0. The
torch.compilefeature and OpenAI Triton language allow developers to write code that compiles efficiently to NVIDIA, AMD, and other backends, significantly lowering the barrier for AMD adoption. - OpenXLA: Supported by Google, AWS, and Apple, this allows JAX/PyTorch models to run on TPUs or GPUs with minimal changes.
8. Strategic Outlook: TCO & Supply Chain
The market has bifurcated into two economic zones. Training requires massive interconnect bandwidth (NVLink), where NVIDIA retains 90%+ share. Inference relies on memory bandwidth and cost efficiency, where AMD and Hyperscalers are gaining ground.
Total Cost of Ownership (TCO): Energy is the new currency. Chips are evaluated on "Tokens per Watt." While NVIDIA's NVL72 requires high CapEx for liquid cooling, it offers density. AMD's air-cooled options offer a lower barrier to entry.
Supply Chain: The dependency on TSMC's CoWoS packaging remains a bottleneck. While NVIDIA secures the majority, the emergence of Samsung and Intel Foundry Services as alternatives in late 2025 is alleviating constraints.
Conclusion
In 2025, the AI chip market is no longer a monopoly; it is an oligopoly defined by workload specificity. NVIDIA has successfully transitioned to a systems company, creating a "walled city" of rack-scale computing unmatched for frontier model training. However, the sheer economic pressure of inference has validated AMD’s high-memory strategy and fueled the rise of hyperscaler silicon.
For enterprise buyers, the choice is now nuanced:
- NVIDIA: For training frontier models and general R&D.
- AMD: For high-throughput inference of open-weights models.
- Hyperscalers: For cost-effective, sticky cloud workloads.
- ASICs: For ultra-low latency, agentic workflows.
The era of "one chip fits all" is over; the era of the specialized AI factory has begun.
